[JAVA] 문자셋(Charset)
문자셋의 역사
2022년 현재를 기준으로 가장 많이 사용되고 많이들 알고 있는 문자셋(Charset)은 UTF-8일 것이라 생각합니다. 물론 여러분들이 프로그래밍을 공부했거나 컴퓨터 공학을 전공했다면 ASCII 뿐만 아리나 UNICODE 등 다양한 문자셋을 알고 있겠죠. 그래서 이렇게 많은 문자셋들이 왜 생겨서 우리를 괴롭히는지 그리고 다 공부해야하는지 궁굼해 하는 분들이 많으실거라 생각하여 짧게 문자셋의 역사와 자주 사용되는 문자셋 몇개를 정리해 보려 합니다.
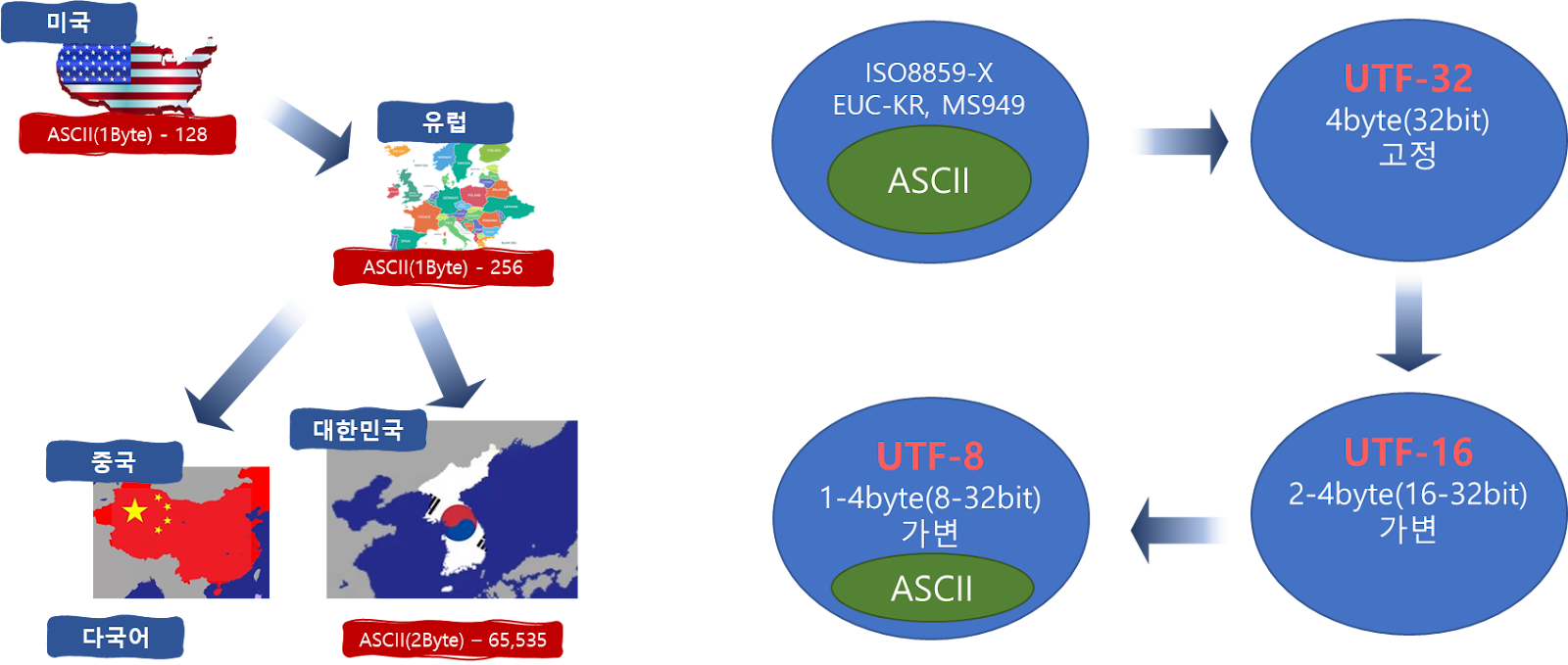
일단 문자셋의 대략적인 역사 또는 발전기를 아래와 같은 그림으로 살펴보도록 하죠.
위에서 보는 바와 같이 최초의 컴퓨터는 알파벳권에서 처음 개발 및 사용되었다고 합니다. 그래서 초기에 컴퓨터를 만들 당시 알파벳만 사용하면 되었던 것이죠. 그 시대 배경을 보더라도 글로벌 시대도 아닌 냉전 시대였으니 뭐 당연한거라고 생각할 수 있었을거 같습니다.
그렇게 시작되었던 초기 컴퓨터에서 0과 1밖에 모르던 컴퓨터에서 사람이 사용하기 위해 글자를 표시할 방법을 컴퓨터 과학자들이 의논하게 되죠. 고민끝에 컴퓨터에서는 데이터를 부호화하는 방법으로 숫자를 문자로 치환하는 방법을 생각하게 됩니다. 예를 들어 0은 NULL 이라는 아무것도 없다라는 기호로 그리고 숫자 65면 문자 알파벳 대문자 ‘A’로 66면 대문자 ‘B’ 이렇게 쭈욱 이어지다가 소문자 ‘a’는 97로 정하게 되죠.
이렇게 사람이 볼수 있는 문자를 컴퓨터 언어인 코드번호로 변경 또는 ‘부호화’하는 방법을 ‘인코딩(Encoding)’ 이라고 하고. 코드번호를 사람이 알아들을 수 있는 문자로 다사 되돌리는 것을 복호화 또는 ‘디코딩(Decoding)’이라고 합니다.
인코딩 : 문자, 숫자, 기호 등을 컴퓨터의 내부처리를 위해 숫자코드번호로 변경하는 것.
디코딩 : 컴퓨터의 내부처리 숫자코드번호를 문자, 숫자, 기호 등을로 다시 복원하는 것.
그래서 처음으로 이러한 기준을 만들었던 것이 ASCII(American Standard Code for Information Interchange : 미국 정보 교환 표준 부호)라고 부르는 우리말로는 아스키코드라고 하는 체계입니다.
아래와 같은 표를 한두번쯤은 보신 분들도 있을거 같습니다. ASCII는 보는 바와 같이 아래의 10진수 코드 0 또는 16진수 0x00을 문자 NULL이라고 정하고 숫자로 보이지만 실제 컴퓨터의 모니터로 표시될 때는 문자 0과 같이 표시되는 ‘0’을 코드 48(0x28)로 그리고 영문 대문자, 소문자 및 특수문자들을 각각 10진(16진) 코드로 규칙을 정해놓은거죠.

자 그런데 여기서 의문이 하나 들기 시작합니다. 그럼 우리 한국처럼 한글을 쓰는 나라는 컴퓨터에 어떻게 한글을 또는 한자를 표시하지? 이 코드로는 안되잖아? 라고요.
처음 아스키코드가 개발될 당시에는 영어 또는 유럽권에서 사용되었기어 위 코드로도 충분했다가 합니다. 위 코드는 컴퓨터의 바이트 또는 비트로 계산해보면 1Byte(8bit) 즉 0 ~ 256개의 코드를 가질수 있죠. 그러니 127개의 위 코드는 충분히 들어갈수 있었던 거죠.
그런데 시대가 또 발전하면서 한글, 중국어, 일본어와 같은 각국의 나라마다의 언어를 표현해야 하는 문제가 발생합니다.
그래서 보다 큰 크기의 문자셋(Charset)가 필요하게 되었고, 이를 위해 먼저 탄생한 문자셋은 유니코드라는 문자셋이었던 거죠.
유니코드는 ASCII가 1바이트에 문자를 표현했던 것과 달리 최대 21비트에 전세계의 문자를 표현할수 있는 지구상에서 통용되는 대부분의 문자들을 담고 있습니다. 또한, 언어를 표기할 때 쓰는 문자는 물론, 악보 기호, 이모티콘 ʕ•ᴥ•ʔ, 태그, 마작이나 도미노 기호, પ નુલુંગ લસશ, ℳα℘ίɕ 같은 것들도 포함되어 있죠.
여기서 한글을 표현하는데 우리는 ㄱ~ㅎ 자음 19개, ㅏ~ㅣ 모은 21개만 있으면 되지 뭐가 많이 필요해라고 생각할수 있습니다. 하지만 컴퓨터에서는 위와 같이 표현하는 것이 상당히 어렵고 힘들므로 컴퓨터에서는 자음/모음으로 코드화하지 않고 아래의 그림과 같이 모든 한글의 글자를 코드로 표현하죠.
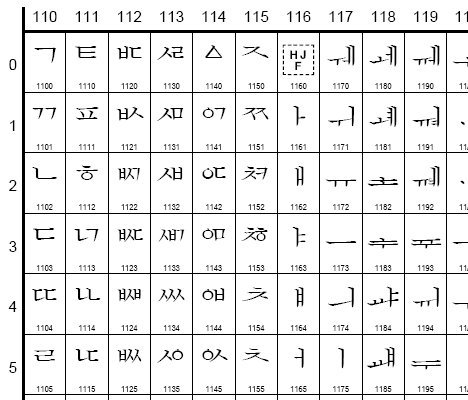
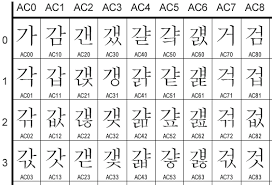
위의 코드가 정확한건 아니고 예를 들어 표시한 것입니다. 즉, 자음/모음 뿐 아니라 가나다라, 각낙닥락, 하물며 사전에도 없는 글자인 갛낳닿 등도 말이죠. 이렇게 모든 자음/모음의 조합을 하나하나 만들어 모두 코드로 부호화 한 것이죠. 지금 제가 갛낳닿을 쓸수 있었던 이유도 위와 같은 코드 체계에 모든 글자들이 담겨있기 때문입니다.
이 조합들이 대략 11,172개라고 하는군요. 그런데 더 심각한 문제는 중국어 였습니다. 중국어의 경우는 한자가 무려 간체가 44,000여개 대만 교육부의 2004년도 사전상으로는 무려 10만개의 한자가 있다고 하네요.
아무튼 결론은 이처럼 다양한 나라의 수많은 글자를 표현할 필요가 있었기 때문에 글자의 코드 크기가 1바이트에서 현재는 2바이트가 주로 사용되지만 상황에따라서는 3바이트를 사용하는 경우도 있습니다.
문자셋의 필요성
그런데 여기서 또다른 문제가 발생하죠. 유니코드가 모든 문자를 표시한다는 관점에서는 성공하였지만 단점으로 크기가 크다는 단점이 이었던거죠. 이 크기가 크다는 문제는 생각외로 컴퓨터 내부에서는 상당히 많은 문제를 발생시킵니다. 간단한 예를 들어 1바이트의 문자를 처리할때 1바이트와 3바이트는 3배의 속처와 처리 능력이 필요하죠. 만약 이걸 10만번 수행해야한다면 어떨까요?
그래서 방법을 찾기 시작했죠. 특별히 나라마다 사용하는 언어는 나라마다 다를거고 나라마다 1~2바이트이면 충분하니 필요할때 그때 그때 문자셋을 추가하거나 변환해서 사용하는 건 어떨까 하고 생각하게 됩니다. 그래서 이러한 방법으로 탄생한 것이 문자셋입니다.
정확히 위에서 언급된 ASCII나 UNICODE는 문자셋이라고 보기보다는 부호화 문자코드라고 하는게 더 정확할거 같습니다.
간단히 말해 문자셋은 위 문자코드들이 커짐에따라 각 상황마다 적당한 셋트를 조합하여 필요에따라 적은 양의 크기로 로딩하여 사용하기 위한 방법이라고 생각하면 쉬울거 같네요.
즉, 예를들어 우리나라처럼 한글, 영문, 숫자, 특수문자 등을 모두 사용한다고 했을때 다 해봐야 2만개가 안될거고 이렇다면 최대로 해서 2바이트(최대 약 6.5만개) 사용하면 되겠죠? 그런데 만약 중국어+영어+일어 등 모든 언어들을 사용한다면 3바이트로도 모자를수 있겠죠? 그래서 각 나라마다 또는 상황마다 문자셋을 만들어 사용하게 되죠.
그러면 한글문자셋에선 0x00ff가 ‘가’라는 글자로 그리고 또 중국문자셋 0x00ff가 ‘韓’으로 표시가 되는것이죠.
물론 위의 예는 간단하게 설명드리기위한 예로 설명을드렸으며 실제의 경우는 코드 및 문자셋이 다른 구조로 되어 있습니다.
그래서 이와 같은 문자셋의 각 세트를 어떻게 부화화하고 복호화하느냐 즉, 인코딩하고 디코딩하느냐의 방식에 따라서 EUC-KR, MS949, ISOxxxx, 및 가장 최근에 많이 사용되는 UTF 방식(UTF-8, UTF-16, UTF-32)이 존재하는 것이죠
위 인코딩 방식에 대하여는 보다 상세한 정보를 알고 싶으시다면 저보다 더 잘 설명한 다른 분의 블로그를 참고하시면 좋을거 같습니다.
문자셋 인코딩 방식 참고 사이트 : https://dingue.tistory.com/16
위 내용중에 UTF-8이 현재는 가장 많이 사용되고 거의 표준으로 자리 잡음에따라 이에 대하여 간단히 설명을 하자면 아래와 같습니다.
먼저 ASCII의 크기 문제로 처음 고안된 것이 모든 문자를 사용하기 위한 UTF-32(4byte 고정)이었습니다. 그런데 여기서 가장 큰 문제는 크기가 4바이트로 무려 ASCII의 4배 2바이트 기준으로도 2배나 크다는게 문제였죠. 그리고 더 큰 문제는 이 크기로 인해 기존의 코드 체계인 ASCII와 전혀 호환이 안된다는 문제가 있었습니다. 그래서 크기를 가변적으로 변경할 수 있는 방법을 찾게되고 이를 UTF-16으로 정의 했죠. 그런데 여기서도 마찬가지로 ASCII와는 호환이 되지 않았습니다. 그래서 마지막으로 정리된 것이 현재 널리 사용되고 있는 UTF-8 인코딩 방식입니다. 이건 뒤의 숫자가 말하는 것처럼 1바이트의 형식이지만 가변적으로 1~4바이트까지 문자를 표현할수 있습니다. 물론 1바이트보다는 2바이트 형식으로 더 많이 사용하지만 정말 중요한건 ASCII와 완벽하게 호환이 된다는 것 때문에 현재 가장 널리 사용되는 인코딩 방식입니다.
자 그래서 위의 내용들을 요약해보면 다으과 같은 그림으로 간략히 표현해 볼수 있을 것 같습니다.
참고 출처 사이트
[Encoding]Character Set에 대해서 알아보자(ecu-kr, utf 등)
아스키 코드, 유니코드 그리고 UTF-8, UTF-16
댓글
댓글 쓰기